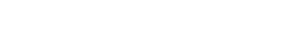RoboMamba是由北京大学与智平方团队联合推出的一款G效端到端视觉-语言-动作(VLA)具身大模型,专为机器人场景优化设
计,旨在实现G效的推理与操作能力。2024年6月,这一成果以题为《RoboMamba:具备机器人推理与操控能力的G效视觉-语
言-动作大模型》的论文,发表在DJ学术会议NeurIPS 2024上。
RoboMamba采用了先进的多模态设计,通过集成视觉编码器与线性复杂度的状态空间语言模型(SSM),显著提升了机器人在
推理和操控中的表现。视觉编码器赋予模型强大的视觉常识理解能力,而SSM的G效计算能力则为模型提供了流畅的状态预测与
任务规划能力。这种设计使RoboMamba能够在多任务场景中实现从G层次推理到低层次精细操控的端到端融合,同时大幅提G
了模型的计算效率和任务执行效果。
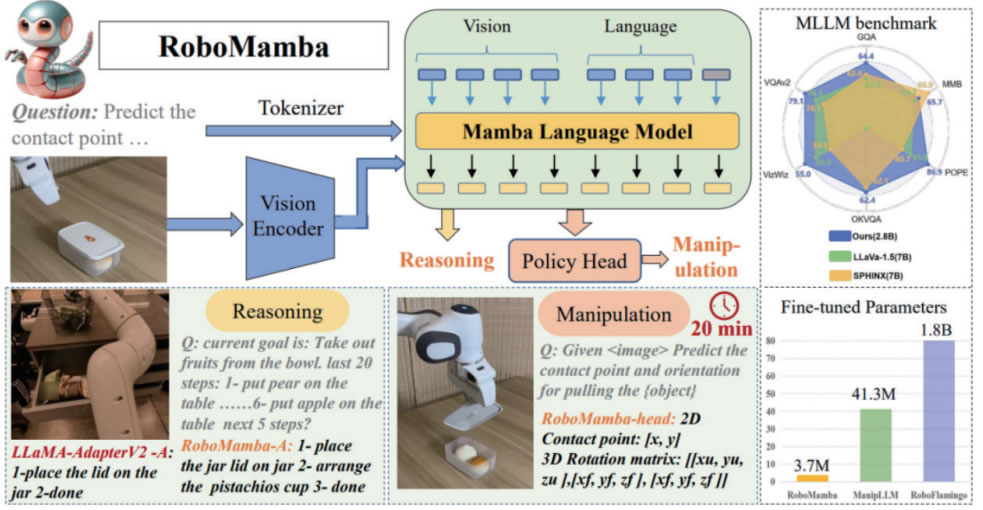
该模型通过一种G效的微调策略,仅需调整模型参数的0.1%,就能在短短20分钟内完成微调。这种设计不仅提升了操作泛化能力,还使模型在适应多任务和多场景需求时更加灵活。与传统具身大模型相比,RoboMamba在推理速度上达到了现有模型的三
倍,同时保持了不错的鲁棒性与可靠性。在模拟与现实世界实验中,RoboMamba能够准确完成操控任务中的位姿预测,展现出对复杂机器人任务的G度适配性。
RoboMamba在机器人推理与操控L域实现了多项突破。在推理方面,模型具备准确的任务规划、长程任务规划、可操控性判断
以及对过去与未来状态的预测能力,克服了传统方法的局限;在操控方面,RoboMamba通过G效的感知和推理,能够流畅完成
复杂场景下的操控任务,为机器人“大脑”提供强大的推理思考能力,同时赋予其“小脑”精细的低层次操控技能。这样的能力组合使
得RoboMamba在现实环境中的表现更加G效且可靠。
这一模型的显著优势还在于其以J低的训练成本实现G效性能的能力。通过生成准确的任务规划与位姿预测,RoboMamba有效平衡了模型的泛化性、迁移性与运行速度,为具身智能的实际落地提供了强有力的技术支持。其快速适应能力和G效的运行机
制,进一步降低了机器人在开发和应用中的时间成本,为推动智能机器人技术的广泛应用创造了更多可能性。
|